YOLOv3
- paper
- You Only Look Once: Unified, Real-Time Object Detection
- YOLO9000: Better, Faster, Stronger
- YOLOv3: An Incremental Improvement
- train - code
- detect - code
paper
- You Only Look Once: Unified, Real-Time Object Detection
1. Introduction
- YOLO9000: Better, Faster, Stronger
Abstract
- YOLO9000은 9000개 이상의 객체 카테고리를 검출할 수 있는 검출 방법이다.
- 기존에는 단일 범위 검출 방법을 사용하였지만 YOLOv2를 사용함으로써 다중 범위 검출 방법을 사용함으로써 다양한 크기에 대해서 학습이 가능하며, 속도와 정확도의 교환이 보다 쉽게 되었다.
- 해당 논문은 검출과 분류를 동시에 학습하는 방법을 제안한다. 이는 COCO 검출 데이터셋과 ImageNet 분류 데이터셋을 동시에 사용한다.
- YOLO9000은 실시간 객체 검출에 있어서 9000개 이상의 다른 객체 범주들을 검출할 수 있으며 정확도 또한 높다.
1. Introduction
- 객체 검출의 일반적인 목적은 보다 빠르고, 정확하고, 가능한 다양한 객체들을 검출하는 것을 목표로 둔다.
- 이러한 객체 검출의 방법들은 빠르게 성장했지만 대부분의 객체 검출 방법들은 여전히 작은 객체를 검출하는데에는 제약이 존재한다.
- 현재 객체 검출 데이터셋들은 다른 데이터셋들에 비해서 분류와 태깅과 같은 부분에 있어서 제약이 많이 존재한다
- 라벨링된 이미지를 많이 가지는 것이 좋지만 이미지에 라벨링을 하는 것은 굉장히 비용이 많이 드는 작업이다.
- 따라서 해당 논문은 기존에 존재하는 라벨들을 이용하여 객체 분류를 해결하는 방법을 제시한다. ( 이 부분이 COCO 와 ImageNet 데이터셋을 동시에 사용하는 부분으로 해결 )
- 이러한 YOLO9000을 사용하면 9000개 이상의 서로 다른 객체들을 검출할 수 있다.
2. Better
- 기존의 YOLOv1은 많은 결점들을 가지고 있었다. 그 중에서도 다른 지역 제안기반의 방법들(region proposal-based methods)들에 비해서 낮은 회기율(recall)을 가졌다.
- 그러므로 YOLO 다음 버전들은 이러한 문제점을 해결해야 함.
- 컴퓨터 시각은 일반적으로 보다 크고, 깊은 네트워크로 가려는 경향이 있다.
- YOLOv2는 그와 반대로 보다 간단하게하여 쉽게 학습하며 정확하지만 여전히 빠르도록 만드려고 한다.
- 다음부터 그를 해결하기 위해서 사용한 방법들을 제시한다.
- Batch Normalization
- YOLO에 있는 모든 Convolutional layer들에 배치 정규화를 사용함으로써 mAP가 약 2% 정도 향상함을 알 수 있다.
- 이는 또한 모델을 규칙화하는데 도움이 된다.
- 또한 모델에 있는 dropout을 제거하더라도 overfitting이 발생하지 않도록 할 수 있다.
-
High Resolution Classifier * 기존의 YOLO는 224 X 224에서 448까지 해상도를 높일 수 있었다. * YOLOv2의 경우는 448 X 448 해상도에서 ImageNet에서 10번의 전체 이미지에 대한 학습 분류 네트워크를 미세조정 하였다. * 이를 통하여 보다 높은 입력 해상도에서 작동할 수 있도록 하였다. * 고 해상도 분류 네트워크는 mAP를 약 4%정도 향상시켰다.
-
Convolutional With Anchor Boxes * 기존 YOLO는 바운딩 박스의 후보들을 예측하는데 fully connected layer를 사용하였다. * 이를 없애고 1X1 Convolutional layer로 대체한다. * YOLO의 Convolutional layer은 input 이미지의 크기를 32배수까지 압축한다. 입력 크기가 416이라면 32배수로 압축시킨 크기인 13까지 압축할 수 있다. * 이를 업샘플링을 통하여 총 3개 크기의 grid cell을 이용할 수 있다. * 기존 YOLO는 한개의 grid cell만 사용하였기 때문에 anchor box의 개수가 하나의 이미지당 98개 였던 반면에 YOLOv2는 천개 이상의 box를 예측할 수 있다. * 이를 통해서 정확도는 조금 떨어지지만 회기율이 높아짐으로써 모델 성능 향상에 유의미함을 알 수 있다.
-
Dimension Clusters * YOLO에서 Anchor box에 있어서 두가지 문제중 하나인 기존에는 손으로 anchor box를 설정함을 언급한다.
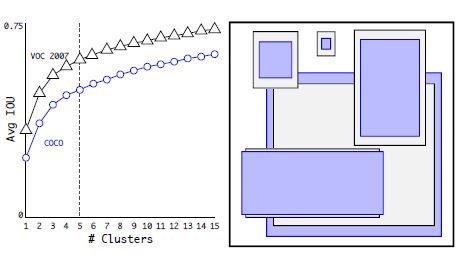
* 위의 그림은 k-means clustering을 통해서 Anchor Box를 결정한 것을 보여준다.
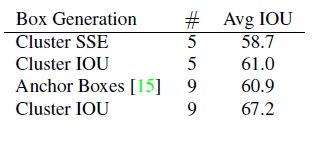
* 위의 표를 보면 알 수 있듯이 손으로 선택한 Anchor Boxes가 9개의 Anchor Box를 사용한 것과 Cluster를 통해서 결정한 Anchor Boxes를 5개 사용한 것이 IOU평균 값이 비슷함을 알 수 있다. - Direct location prediction
- 두 번째 문제는 모델의 불안정성을 언급한다.
- 이러한 문제는 x,y 좌표를 예측하는데 있어서 발생한다.
- 네트워크는 총 5개의 값 tx,ty,tw,th,to를 예측한다.
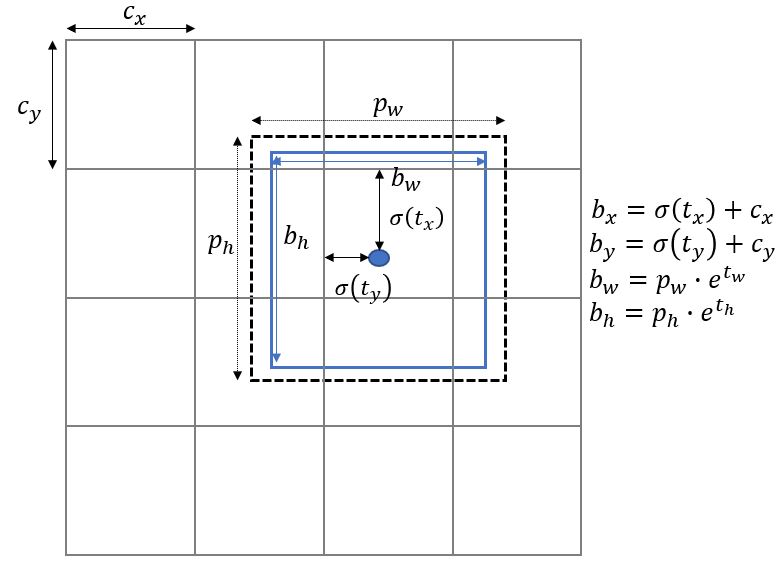
- 위의 식을 사용하여 예측할 수 있다.
- 이를 통해서 약 5%이상의 성능 향상을 알 수 있다.
-
Fine-Grained Features * 간단하게 가장 많이 다운샘플링한 레이어(32배수만큼)를 다음 업샘플링한 레이어(16배수)로 연결시켜주는 작업을 통해서 Faster R-CNN과 SSD와 차별성을 두었다. * 이를 통해서 약 1% 성능 향상을 얻을 수 있다.
- Multi-Scale Training
- 10번의 Batch마다 이미지의 크기를 변경시켜주는 작업을 함.
- 또한 학습 데이터의 입력 크기에 따라서 속도와 정확도를 교환할 수 있다.
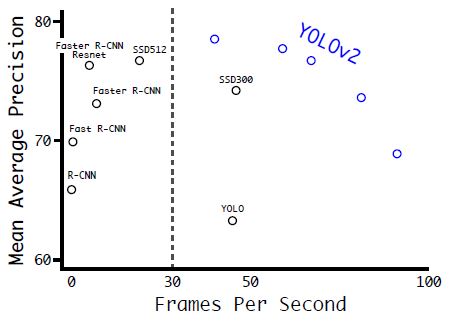
- 위의 그림을 보면 YOLOv2의 성능이 전체적으로 우수한 것을 알 수 있다.
3.Faster
- 대부분의 방법들은 VGG-16 기반으로 특징을 추출한다. VGG-16은 강력하며 정확하지만 복잡한 문제가 존재한다.
- VGG-16은 300억 6900만의 부동 소수 연산자들이 224 X 224 해상도에서 단인 이미지당 필요하다.
- YOLO는 Googlenet architecture기반을 사용한다. 이는 VGG-16보다 빠르며 오직 80억 5200만개의 연산자들이 필요하다. 그러나 정확도는 VGG-16은 90%인 반면 YOLO는 88%를 얻는다.
- Darknet-19
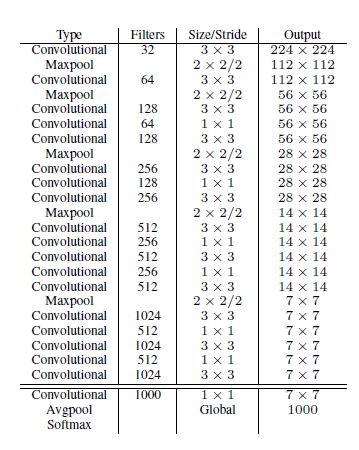
- 해당 방법은 총 19개의 Convolutional layers 와 5개의 maxpooling layers을 사용한다.
- 결과론적으로 Darknet-19는 오직 50억 5800만 개의 연산자들이 필요하며 정확도 또한 높다.
Training for classification
- 모델의 부수적인 값들에 대한 설명을 한다. 해당 부분은 소스를 보면서 공부하는 것이 보다 이해하기 좋을 것이라고 생각됨.
다음 내용들은 classification에 관련된 내용들이므로 이 부분에 대해서는 추가적으로 언급을 하지는 않을 예정. ( 필자는 객체 검출에 있어서도 사람에 대한 객체 검출만 하는 것을 공부하고 있기 때문에 추후 필요할 경우 공부할 예정 )
- YOLOv3: An Incremental Improvement
Introduction
train - code
소스 분석은 darknet에서 참조하여 공부하였다.
만약 수정하고 있는 source을 참조하셔도 좋습니다.
학습 정리 페이지 : [Train_part]
detect - code
검출 정리 페이지 : [Detect_part]